Approximate Standard Normal Distribution CDF
Some time ago I came across one book called Street-Fight Mathematics. I found it extremely interesting and useful. It consists only of 150 pages, but it covers a lot of awesome problem solving techniques. You can actually download the book for free or buy it, though there’s a free copy available it’s still worth paying.
There’s one particular problem in this book that caught my attention. It is Standard Normal Distribution CDF approximation. If you check the Wikipedia you will find that many solutions can be used to produce extremely accurate approximation. I checked proofs for two of them and I found that they include some amount of calculus which can be challenging for some people. But methods from the book don’t require calculus knowledge to make such an approximation. We don’t even need to get into advanced maths, just heuristics and simple math operations. So, let’s look at the solution step by step.
First of all let’s check the Standard Gaussian PDF \((1)\).
\[f(x) = \frac{1}{\sqrt{2 \pi}} \cdot e ^ {\frac{-x ^ 2}{2}} \tag 1\]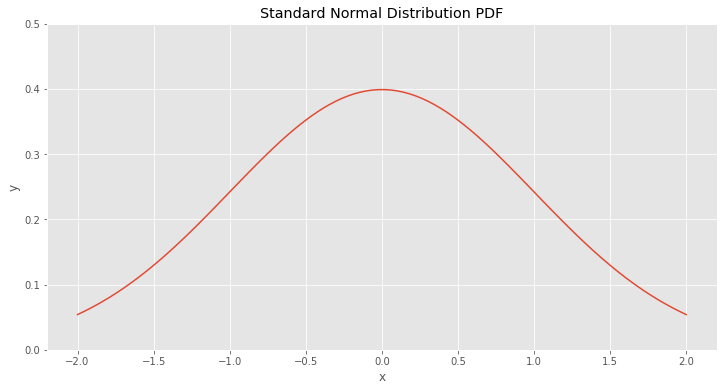
For the gaussian (the figure above) we need to find a function that returns area under the PDF function for \(x \in (-\infty, a]\) where \(a \in \Bbb R\). In other words it’s a CDF \((2)\).
\[\begin{align} F(x) & = \int _ {-\infty} ^ {x} f(t) \;dt \\\\ & = \frac{1}{\sqrt{2 \pi}} \int _ {-\infty} ^ {x} e ^ {\frac{-t ^ 2}{2}} \;dt \end{align} \tag{2}\]Let’s plot it next.
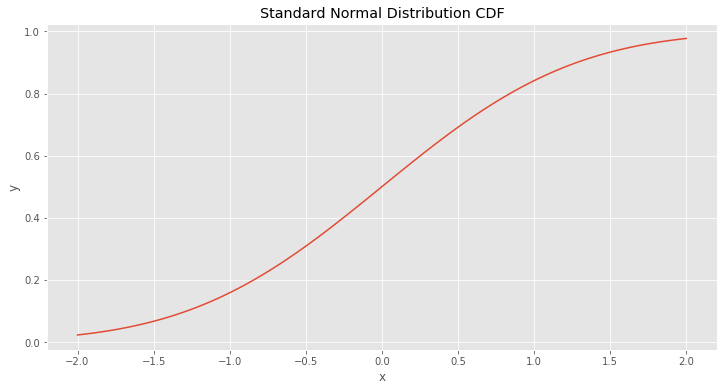
The problem is that there is no elementary function that can perfectly fit function that is shown above. A good news is that, we can approximate it. In real life applications we don’t need the exact answer, we just interested in a very close one.
From the previous figure it is clear that function is odd. Therefore, we can compute only the half of CDF where \(x \in (-\infty, 0]\) and using function’s symmetry to find the rest.
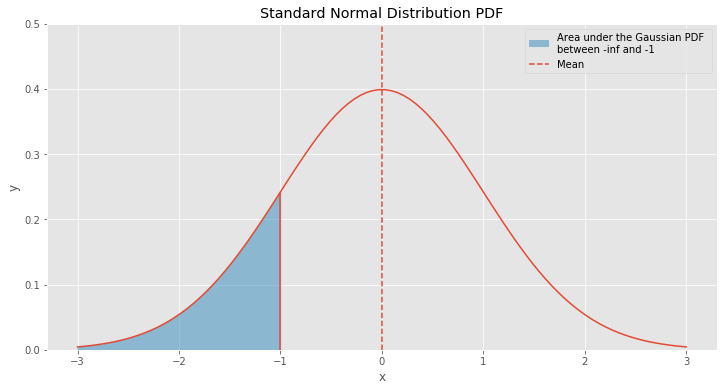
Let’s think a little bit about the problem. What do we actually need? We need to find the area. Which 2D object has the most simple formula for the area? It’s a rectangle. To find it we just need to multiply width by height. Let’s try to find rectangle that approximates the CDF. In the figure below pictured the same Gaussian PDF, as in the previous figure, but only for \(x \in [-3, 0]\).
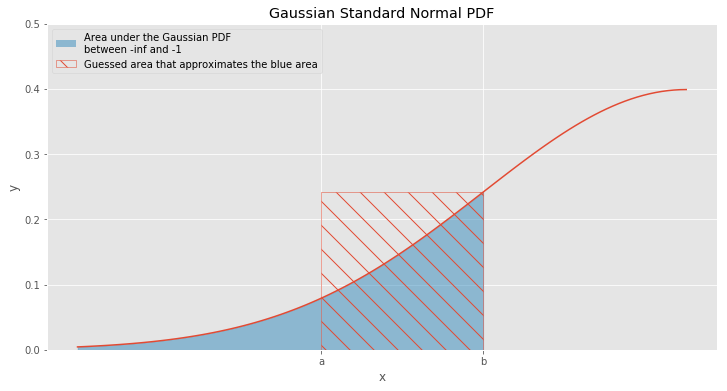
In the figure above you can find a rectangle filled with oblique lines. This rectangle got the biggest part of the blue area. In addition, it also caught a lot of region that is under the curve and didn’t catch an infinitely long “tail” on the left. We can think about this rectangle in more intuitive way. Let’s say that we have a box and we would like to fill it with some long cloth. We already put the biggest part of the cloth and now we need to place the rest of it inside. Since we have some space left, we can fill it with the rest of the cloth.
There are two heuristics that can determine box’s width and height. The first method that we are going to use is a \(1 / e\) heuristic. The main idea of this heuristic is the need to find a point \(x\) that identifies significant changes of function. There is no clear definition of “significant change” that’s why we need some rule that can help us identify something that is close to it. For the 1 / e heuristic function’s significant change means that function minimizes its maximum value by factor of \(e\).
\[f(a) = \frac{1}{e} \cdot f(b) \tag 3\]Where \(b\) is the value that identifies right bound for the that approximates function that we’re interested in. And \(a\) is the point that identifies function’s significant change. \(a\) is also the left side bound for this rectangle. Gaussian PDF is monotonically increasing for \(x \in (-\infty, 0]\), therefore, the maximum value \(x\) identifies function’s maximum. We can detect it using simple algebraic operations.
\[\frac{1}{\sqrt{2 \pi}} \cdot e ^ {\frac{-a ^ 2}{2}} = \frac{1}{e} \cdot \frac{1}{\sqrt{2 \pi}} \cdot e ^ {\frac{-b ^ 2}{2}} \tag 4\] \[e ^ {\frac{-a ^ 2}{2}} = \frac{1}{e}\cdot e ^ {\frac{-b ^ 2}{2}} \tag 5\] \[e ^ {\frac{-a ^ 2}{2}} = e ^ {\frac{-b ^ 2}{2} - 1} \tag 6\] \[e ^ {\frac{-a ^ 2}{2}} = e ^ {\frac{-b ^ 2 - 2}{2}} \tag 7\] \[a ^ 2 = b ^ 2 + 2 \tag 8\] \[a = \pm \sqrt{b ^ 2 + 2} \tag 9\]Since \(a < 0\),
\[a = - \sqrt{b ^ 2 + 2} \tag{10}\]Now we are able to find the \(1 / e\) heuristic’s CDF approximation.
\[\begin{align} F(x) & \approx \Phi_e(x) \\\\ & = (b - a) \cdot f(x) \\\\ & = (x - (-\sqrt{x ^ 2 + 2})) \cdot f(x) \\\\ & = \frac{1}{\sqrt{2 \pi}} \cdot (x + \sqrt{x ^ 2 + 2}) \cdot e ^ {\frac{-x ^ 2}{2}} \end{align} \tag{11}\]Formula \((11)\) is a rough approximation for the Gaussian CDF. We can plot approximation and compare it to the real CDF function.
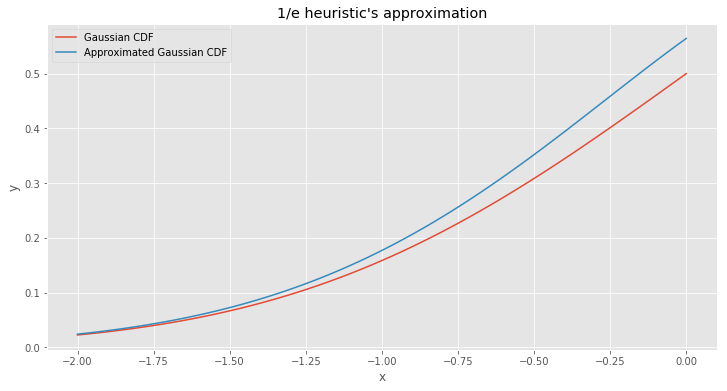
Not bad for such a simple technique. It seems like this method overestimates the real value. It happened because we set up rectangle width to big. Let’s check another heuristic known as Full width at half maximum or FWHM. The idea is the same as for \(1 / e\) heuristic, but instead of the factor \(e\) it uses a factor of \(2\). We need to perform the same calculations as we did for the heuristic above and repeat the same steps from \((4)\) to \((10)\). I didn’t want to repeat the same calculations again so I only wrote the final result.
\[a = - \sqrt{b ^ 2 + 2 \cdot ln(2)} \tag{18}\] \[\begin{align} F(x) & \approx \Phi_{fwhm}(x) \\\\ & = \frac{1}{\sqrt{2 \pi}} \cdot (x + \sqrt{x ^ 2 + 2 \cdot ln(2)}) \cdot e ^ {\frac{-x ^ 2}{2}} \end{align} \tag{19}\]Let’s check the new approximation.
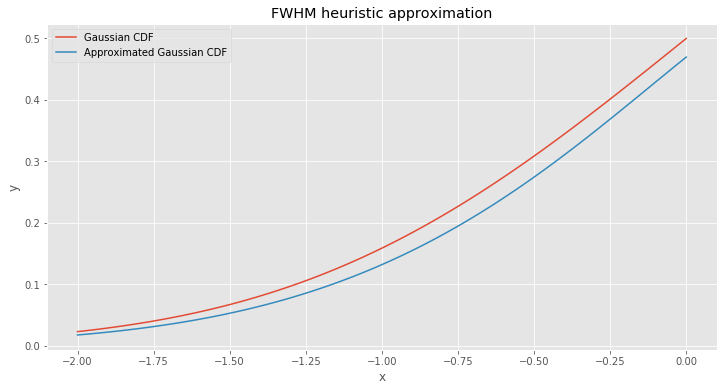
Still not bad. But this time the result is an underestimate. Now we have two solutions that have different error signs, therefore, we can average them to reduce approximation error.
\[\Phi _ {avg}(x) = \frac{\Phi _ e(x) + \Phi _ {fwhm}(x)}{2} \tag{20}\]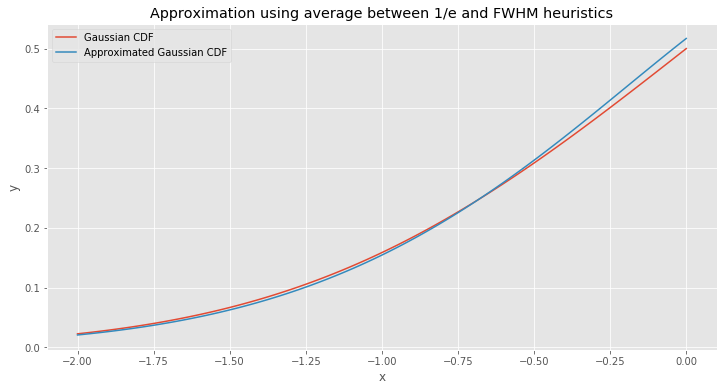
Isn’t it awesome? Such a simple algebraic method produces such an accurate result.
But that’s not all. We just approximated a half of the Gaussian CDF, but the main task is to find an entire CDF approximation. Since the function has a symmetry we can copy and rotate \(\Phi_{avg}\) function to \(x > 0\).
\[\Phi_{1}(x) = \begin{cases} \Phi_{avg}(x), & \text{if $x \le 0$} \\\\ 1 - \Phi _ {avg}(-x), & \text{otherwise} \end{cases} \tag{21}\]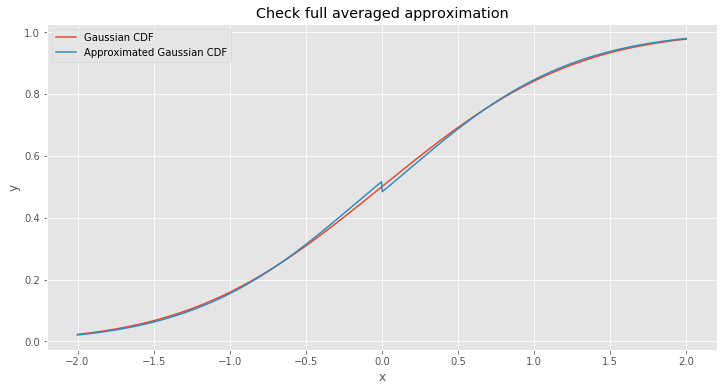
The strange leap at zero mark looks ugly. But why did it happen? The problem is that we expect that \(g(0) = 0.5\). But with our approximation we have different value for \(x = 0\) when we approach it from different sides. From the left side function approaches to \(\approx 0.517\) and from the right side
- to \(\approx 0.483\). We can cut CDF approximation result and set up everything that greater then \(0.5\) equal to \(0.5\). Let’s try it.
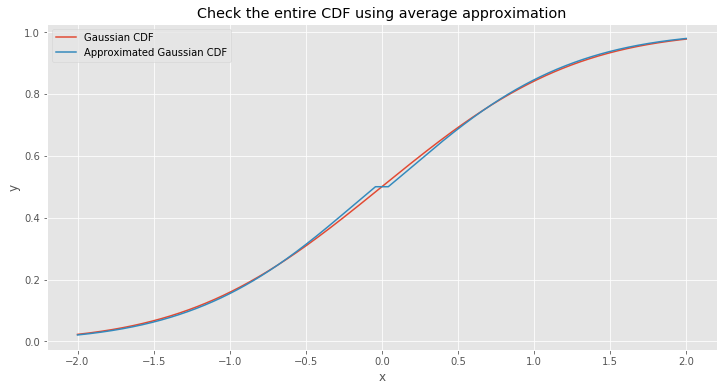
Looks better. But still this junction at \(x = 0\) looks strange.
Now I’m going to reduce the approximation error. This procedure involves approximation error calculation from CDF that we used for comparison before. Typically, it’s not possible to identify this error for each value of \(x\), the way we continue solving this problem will include some additional information about function which can be inaccessible for dealing with other tasks.
To reduce the approximation error we need to understand the nature of the error. It helps us compute the difference between the real CDF and its approximation. In the figure below you can spot this difference.
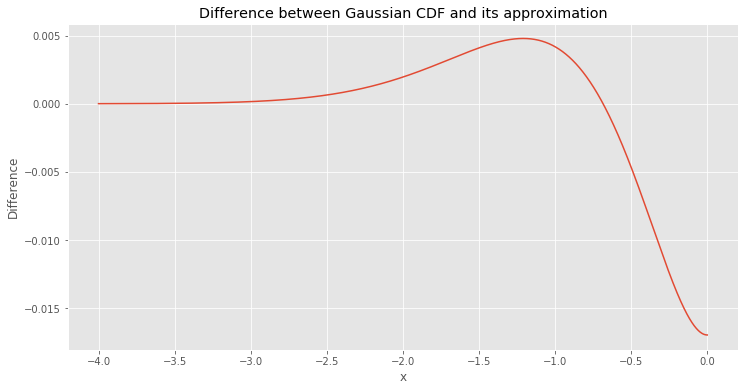
As we can see from the figure above, the biggest error is in the region \([-2.5, 0]\). To fix this problem we need to guess the function that can fit the one plotted above. If we knew what function can match the one above, we would be able to add it to the CDF approximation. This particular trick could help us reduce the approximation error. But the function above is definitely not the simplest one to guess.
Let’s give this problem a try. What do we know about this function so far. It seems like function should have an asymptote approaches to \(0\). What else? Probably the function should have a nice and smooth junction at point \(x = 0\) which is \(\Phi_{avg}(0)\).
I started with a function that suited previous two observations. It is an inverse tangent (or arctangent). I know that it looks completely different, but at least it can reduce the biggest part of error.
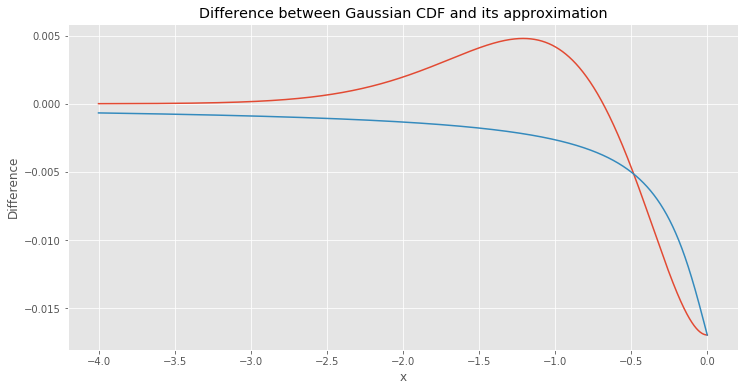
The inverse tangent fuction helped us reduce the biggest error, but we can do better. After some research I found that this function above looks very similar to the second derivative of the hyperbolic tangent function, which is a common choice for activation function in Artificial Neural Networks.
\[{d ^ 2 \over dx ^ 2} tanh(x) = -2 \cdot tanh(x) \cdot sech ^ 2(x) \tag{23}\]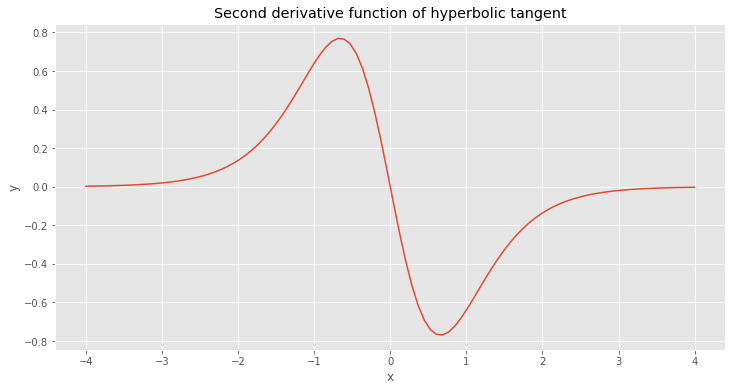
It looks good as for second guess, but we definetly need to stretch it a bit. I iteratively guessed parameter values, just to make this process as quick and simple as possible. It took just a few minutes. All iterations can be viewed in the next figure.
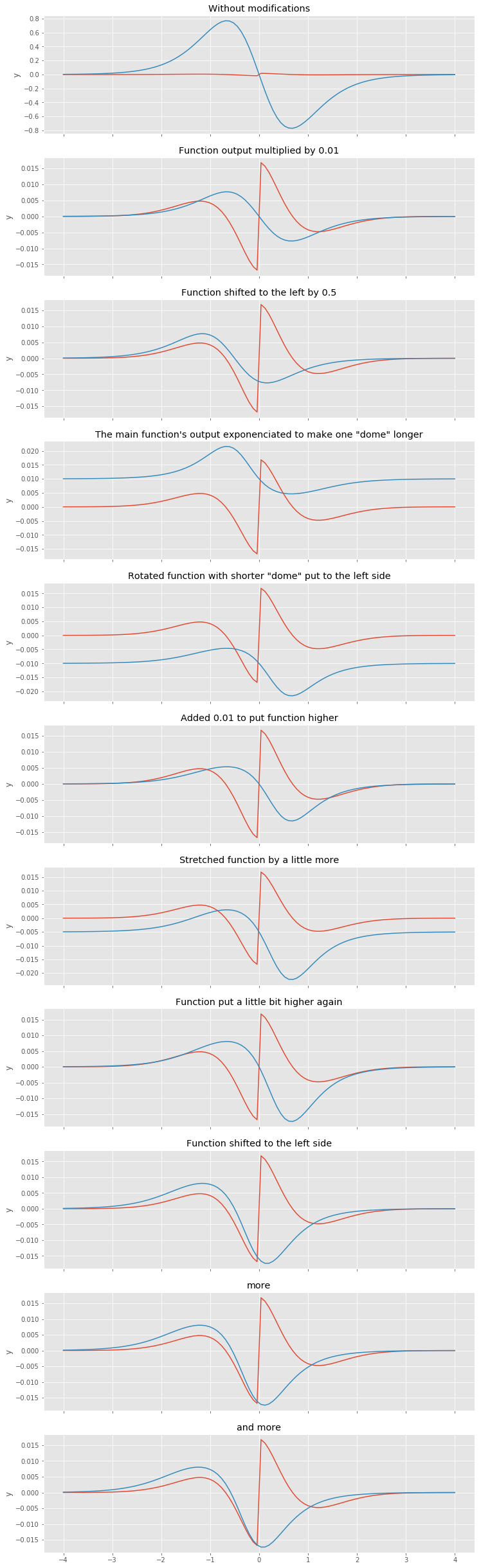
Looks like the last one suits our needs just fine. The final formula \((23)\) is shown below.
\[r(x) = -0.015 \cdot exp ^ {-2 \cdot tanh(-x - 0.58) \cdot sech ^ 2(-x - 0.58)} + 0.015 \tag{24}\]I added this function to the last approximation \((22)\) and that’s what I got.
\[\Phi_3(x) = \begin{cases} \Phi _ {avg}(x) + r(x), & \text{if $x \le 0$ and $\Phi _ {avg}(x) + r(x) < 0.5$} \\\\ 1 - \Phi _ {avg}(-x) - r(-x), & \text{if $x > 0$ and $\Phi _ {avg}(-x) + r(-x) < 0.5$} \\\\ 0.5, & \text{otherwise} \end{cases} \tag{25}\]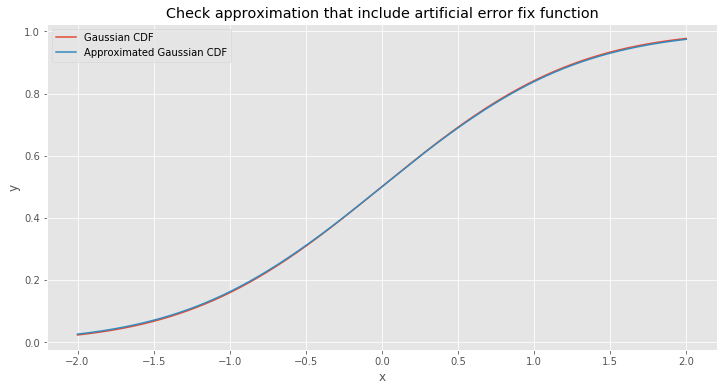
Awesome! Looks like it fit very well. Even though with this approximation we have one problem. There are some areas with a huge error. This problem is not very visible in the picture above but it does exist. But if we take a look at small values of \(y\) we will notice that error is very obvious down there. The problem is that guessed function error approximates \(y = 0\) much slower than the CDF and difference can be even hundreds times bigger for very small values. Below I plotted a percentage of error for the values between -5 and 5.
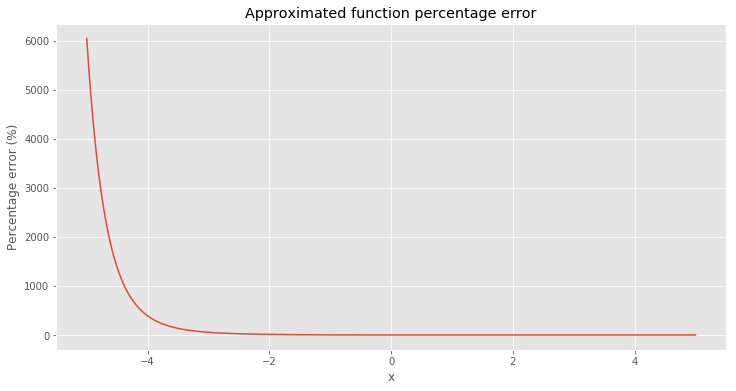
For example, value for \(-10\) approximately equals to \(8 \cdot 10 ^ {-10}\) and real CDF value for the same point is approximately \(7.6 \cdot 10 ^ {-24}\). In most cases we won’t care about such small numbers. The easiest way to fix that problem is to cut a tail from the guessed error function.
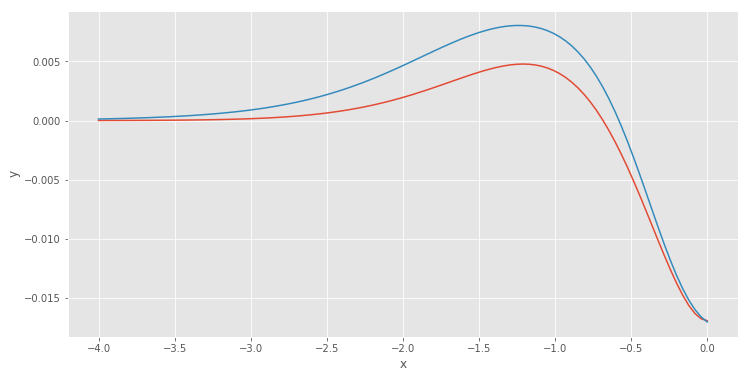
The figure above shows that error difference become less apparent at \(x < -2\). Therefore, we can set up guessed error function to zero for all \(x < -2\).
The other problem is that for some values of \(x\) function is not smooth. In the figure below we can see two examples.
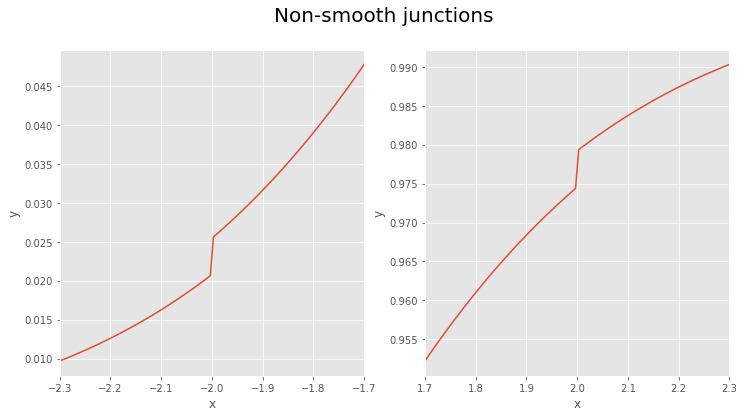
The remaining problems are not really that big and CDF approximation gives us pretty good result. For simplicity we can ignore this problem.
Below I provided the entire formula for the CDF approximation.
\[\Phi(x) = \begin{cases} \Phi _ {avg}(x) + r(x), & \text{if $x \le 0$ and $\Phi _ {avg}(x) + r(x) < 0.5$} \\\\ 1 - \Phi _ {avg}(-x) - r(-x), & \text{if $x > 0$ and $\Phi _ {avg}(-x) + r(-x) < 0.5$} \\\\ 0.5, & \text{otherwise} \end{cases} \tag{25}\]where
\[\begin{align} & \Phi _ {avg} (x) = \frac {2x + \sqrt{x ^ 2 + 2} + \sqrt{x ^ 2 + 2 \cdot ln(2)}} {2} \cdot f(x), & \text{for $x \le 0$} \end{align}\] \[f(x) = \frac{1}{\sqrt{2 \pi}} \cdot e ^ {\frac{-x ^ 2}{2}}\] \[r(x) = -0.015 \cdot exp ^ {-2 \cdot tanh(-x - 0.58) \cdot sech ^ 2(-x - 0.58)} + 0.015\]Formula is definitely not among the simplest ones, but methods that produced it are simple and straightforward.