Chaining ranges with SQL
Problem
Let’s say we have an office that can be accessed only using an ID card. Each time an employee enters and leaves the office we record this event as a row in the database. In the database, we store user ID, time when an employee entered and left the office. We want to write a query that extracts all time ranges when there was at least one person in the office.
Example
Let’s say we have 3 employees with IDs E1, E2 and E3. We recorded their
data for some time and these are the ranges that we got
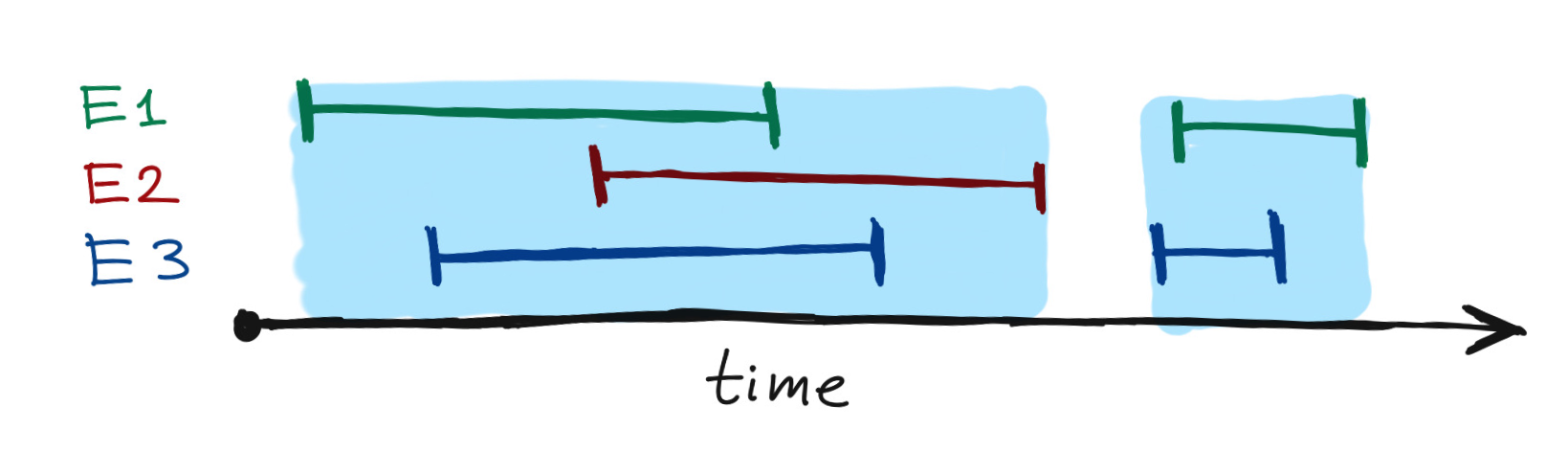
With this example we will want to end up with only two ranges (indicated by the blue area on the image). Basically, we want to chain all of the overlapping ranges into a single range.
Definitions
I think it might be important to define a few terms in order to simplify explanations in the subsequent sections.
- Range - data structure which captures a timeline specified between two points, namely start and end time. For example, we can define range with the following expression \(r_i = (s_i, e_i)\) where \(s_i\) and \(e_i\) are start and end time of the range respectively.
- Super range - range that could be obtained after chaining all connected ranges into a single range. We will use an upper case notation for these ranges \(R_i = (S_i, E_i)\). It’s important to note that super ranges do not overlap, otherwise they could be combined into bigger super ranges which contradicts the main definition.
- Overlap - We consider that two ranges \(r_i\) and \(r_j\) overlap if and only if \(s_i \leq e_j\) and \(s_j \leq e_i\)
Easy solution (non SQL)
Although the main idea for this article is to build an algorithm that solves this problem with SQL query I think it might be important to show the easiest solution first.
Let’s imagine that we start with a set of super ranges and assume that we don’t know anything about the original ranges (it could be seen as an inverse problem). Super ranges have useful property which normal ranges don’t have - they do not overlap with each other.. We can sort them either using start or end time and end up with the sequence that has the following property \(S_i \leq E_i < S_{i+1} \leq E_{i+1}\) (one super range will be a special case for which \(i=1\) and 2nd range doesn’t exist). Even if we don’t know what ranges do we have we can say for sure that \(S_i \leq s_k \leq e_k \leq E_i\) from which we can see that \(s_k \leq e_k < S_{i+1} \leq E_{i+1}\). This indicates that if we sort values by start (or end) time we will never mix ranges among different super ranges, for example, we won’t be able to get range which belongs to super range \(i\) in between ranges from super range \(k\) after the sorting. This significantly simplifies the problem and this observation shows that sorting creates order between super ranges which we can exploit.
This could be easily exploited by a simple loop where we first sort all ranges using their start time (order is not important for ranges that have exactly the same start time). Next we copy the start and end time of the first range and create a super range out of it. Then we compare if the current super range overlaps with the second range. If they do overlap than we merge current super range with the second range using the following rule
\[R_i = (S_i, max(E_i, e_j))\]Note that we intentionally do not find a smaller start time since the super range will always have the smallest start time compared to all of the subsequent ranges (because of the sorting operation).
In the second case, if the super range and the second range do not overlap then we store the current super range and copy the second range in order to form a new super range. The whole process continues until we process all of the ranges. Every subsequent range will be either merged with the current super range or transformed into the new super range.
It’s easy to show that this process will always produce desirable results and we can prove it by contradiction. Let’s assume that logic breaks somewhere. We showed already that ranges that belong to different super ranges cannot be mixed if we sort by start or end time. In addition, we know that ranges from different super ranges do not overlap which means that we cannot assign range to a wrong super range and this leaves us with one last potential problem. Maybe we incorrectly divided ranges into two super ranges when they should have been combined into a single super range. Let’s assume that something like this happened. Let’s say we find a range in our sorted sequence where this problem occurs for the first time (none of the previous ranges in the sequence had this problem).
| Range Index | StartTime | EndTime |
|---|---|---|
| … | … | … |
| \(r_{i-1}\) | \(s_{i-1}\) | \(e_{i-1}\) |
| \(r_i\) | \(s_i\) | \(e_i\) |
| … | … | … |
Let’s say that the current super range is \(R_k = (S_k, E_k)\) and we didn’t manage to assign \(i\)-th row to the current super range and accidentally created a new super range out of it. If this is true then this implies that the current super range \(R_k\) doesn’t overlap with the range \(r_i\), or a bit more specifically \(E_k < s_i\). We know that range \(r_i\) must be a part of the same super range, which means there must be at least one range \(r_j\) which captures some time outside of the current super range and this range should have \(E_k < e_j\). In addition, it should overlap with the current super range so that \(s_j \leq E_k\). These properties create a problem since we’ve learned that \(s_j \leq E_k < s_i\) and this statement implies that there must be another range which appears before \(r_i\) and extends the current super range which means either there is one range missing between \(r_{i-1}\) and \(r_i\) or there is one more range before \(r_{i-1}\) which should have been accepted to the current super range (otherwise \(r_{i}\) can’t be the first mistake). The last option leads to another contradiction, since we assumed that relation between the current super range \(R_k\) and range \(r_j\) has the following property \(E_k < e_j\) which indicates that range \(r_j\) hasn’t been merged with super range \(R_k\). This contradiction shows that the algorithm works for any set of ranges.
Although this algorithm is simple it might be difficult to maintain state in SQL query (i’m not taking into account variable declarations which are present in MySQL). There is another solution that allows us to take advantage from some general functions available in most SQL languages. In addition to SQL, the same solution could be implemented using pandas or spark data frames.
Disclaimer: In the previous paragraphs the term super range is being referred to a super range of the subset of ranges that has been observed and it doesn’t contradict the definition of the term super range.
Solution
In this section, I’ll briefly explain the algorithm and more details could be found in the next section which includes proof that this algorithm will produce correct result for any set of ranges.
First, we need to define a schema for a table which will store the ranges.
CREATE TABLE OfficeStay (
Id INT NOT NULL AUTO_INCREMENT,
UserId INT NOT NULL,
TimeEntered INT NOT NULL,
TimeLeft INT NOT NULL,
PRIMARY KEY (Id)
);In general, for relational databases or spark it’s difficult to maintain state which we need for the simplest approach and in order to avoid having state we can start by finding overlaps between every possible pair of ranges. This could be done with the self-join operation.
SELECT
o1.TimeEntered as StartTime,
MAX(GREATEST(o1.TimeLeft, o2.TimeLeft)) as EndTime
-- Join to the same table in order to find all
-- ranges that overlap (including self-overlaps)
FROM OfficeStay as o1
JOIN OfficeStay as o2 ON
-- This condition checks if two ranges overlap
o1.TimeEntered <= o2.TimeLeft
AND o2.TimeEntered <= o1.TimeLeft
GROUP BY StartTimeNext, we can sort all of the discovered pairs using start time and end time and
find the EndTime difference between two subsequent rows using the function
applied per each window.
WITH OverlappingRanges AS (
-- Previous query goes in here
)
SELECT
StartTime,
EndTime,
-- 1 indicates when new range starts
-- 0 indicates that row should be included
-- into same range as previous range
IFNULL(
(StartTime - LAG(EndTime, 1) OVER (ORDER BY StartTime)) > 0,
0
) as DoesOverlapWithPrevRow
FROM OverlappingRangesAnd with these results we can just use cumulative sum in order to convert binary indicators to range identifiers.
WITH RangesWithRangeIds AS (
WITH SubsequentOverlappingRanges AS (
-- Previous query goes in here
)
SELECT
StartTime,
EndTime,
-- Cumulative sum
-- +1 when new range starts (range that doesn't
-- overlap with range in the previous row)
-- +0 when range remains unchanged
SUM(DoesOverlapWithPrevRow) OVER (
ORDER BY StartTime
) as RangeId
FROM SubsequentOverlappingRanges
)
SELECT
MIN(StartTime) as StartTime,
MAX(EndTime) as EndTime,
RangeId
FROM RangesWithRangeIds
GROUP BY RangeId;Prove
It can be proved by contradiction that this algorithm works for any possible set of ranges. But first we need to understand the first step a bit better. We used the following function to merge two ranges
\[f((s_1, e_1), (s_2, e_2)) = (s_1, max(e_1, e_2))\]Function is not symmetric, meaning that for the general case this condition is not true, because the start time of the new range will depend on the first range which was passed to the function.
\[f((s_1, e_1), (s_2, e_2)) = f((s_2, e_2), (s_1, e_1))\]Next, it’s important to note that SQL returns both pairs, meaning both pairs will be present in the final list of the results. Basically, each range \(r_i\) will be replicated \(N_i\) times where \(N_i\) is equal to the number of ranges that overlap with the \(r_i\) range (including \(r_i\), which means \(N_i \geq 1\))
Although this procedure creates a lot of new ranges (which are large or the same length as the original range) it doesn’t change the result. We can have two ranges \(r_i\) and \(r_j \) which overlap. If we keep these ranges and add a new range which combines two of these ranges this won’t have any effect on the final result. Out of all the ranges that have exactly the same start time we will pick the one that has the largest length. This operation helps to get rid of the ranges that won’t have any impact on the final result. Next, we sort all ranges using start time (which is a unique value) in the ascending order.
It’s easy to show that previous steps do not create a problem. But it’s not obvious that windowing won’t create a problem and we need to prove it separately.
Let’s assume that we applied a first step and merged all of the overlapping ranges. We can assume that there exists a set of ranges from which the algorithm will produce an incorrect result and the first mistake occurs at the i-th row.
| Index | StartTime | EndTime |
|---|---|---|
| … | … | … |
| \(i-1\) | \(s_{i-1}\) | \(e_{i-1}\) |
| \(i\) | \(s_i\) | \(e_i\) |
| … | … | … |
We can have only two types of mistakes. Either two ranges should belong to two different super ranges, but we assign them to the same super range or the other way around.
We’ve already figured out that we never create ranges outside of the super range, which means if \(i\)-th range overlaps with the previous range then they must be a part of the same super range and we cannot assign them to the wrong super range.
Unfortunately it’s not that obvious that we will always assign every range to the correct super range. Let’s assume that a problem like this occured for the first time at the \(i\)-th index. This means that \(i\)-th and \((i-1)\)-th indices should belong to the same super range, but there is no overlap between them and for this reason algorithm had to assign \(i\)-th range to a new super range. Basically, this statement implies that \(s_{i-1} \leq e_{i-1} < s_i\). But since we know that these two ranges belong to the same super range than there must be at least one more range \(r_k\) that has \(s_k < s_{i} \leq e_k\) (\(r_k\) might not overlap with \(r_{i-1}\)). We know for sure that \(s_k \neq s_{i-1}\) because of the deduplication that has been implemented in the previous step. This means \(r_k\) should be before \(r_{i-1}\) or we can say that \(s_k < s_{i-1}\). This also implies that \(r_k\) and \(s_{i-1}\) must overlap, because \(s_k < s_{i-1} < e_{i-1} < s_i \leq e_k \). And since \(r_k\) and \(s_{i-1}\) overlap we know that in the previous range there should have been range \((s_{i-1}, e_k)\). Since we have only one range which starts with \(s_{i-1}\) this implies that \(e_k = e_{i-1}\) which is a contradiction.
Since every possible path leads to a contradiction this proves that the algorithm should work for any set of ranges.
Source code
All of the code for this solution with a few examples could be found on Github